Notes
Structures
Mesh
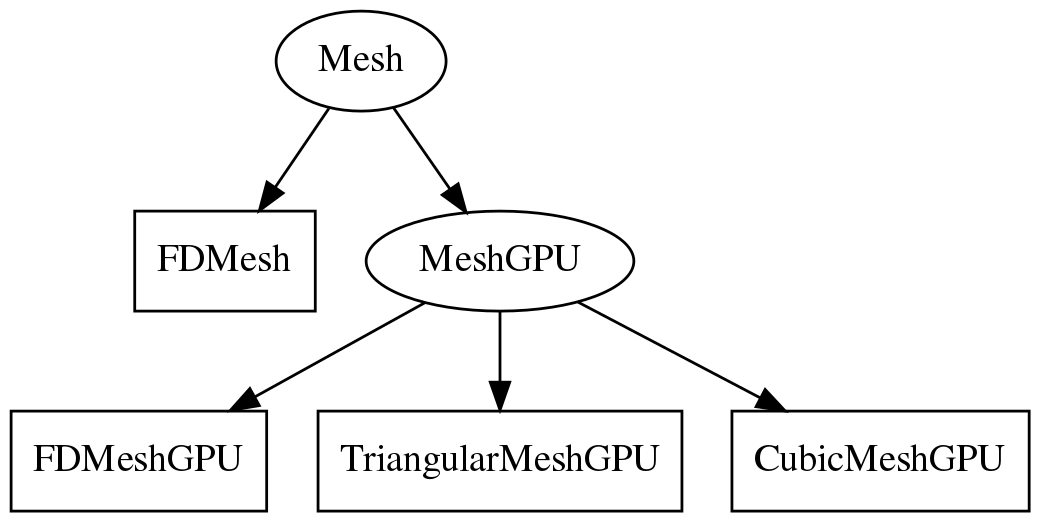
Sim
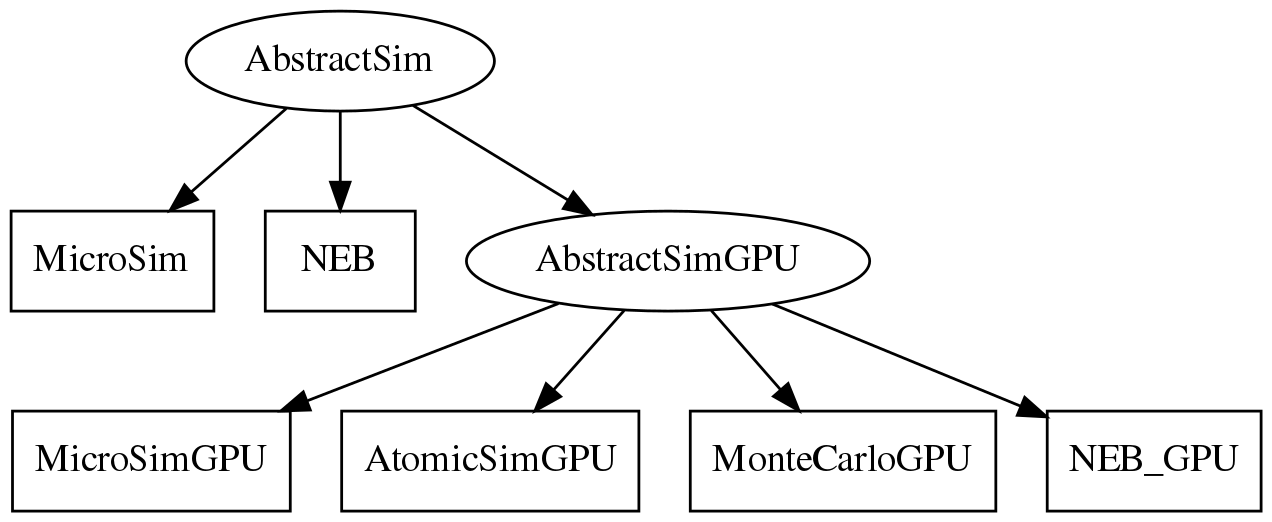
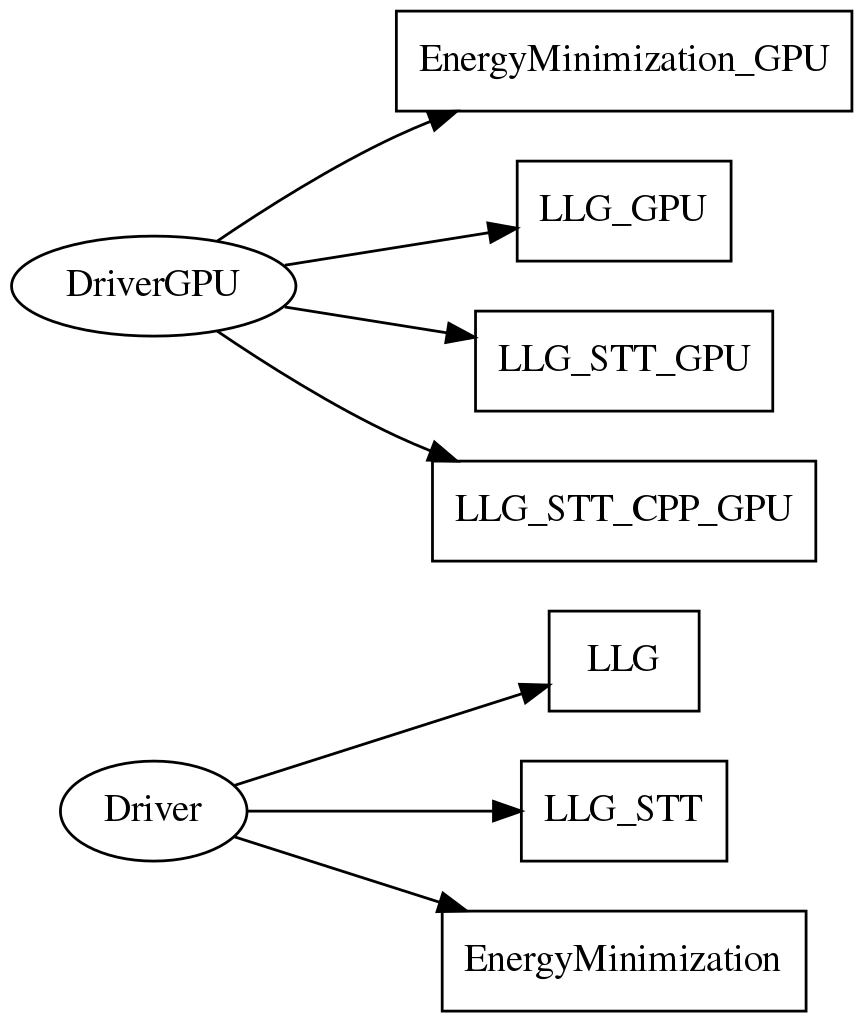
Driver
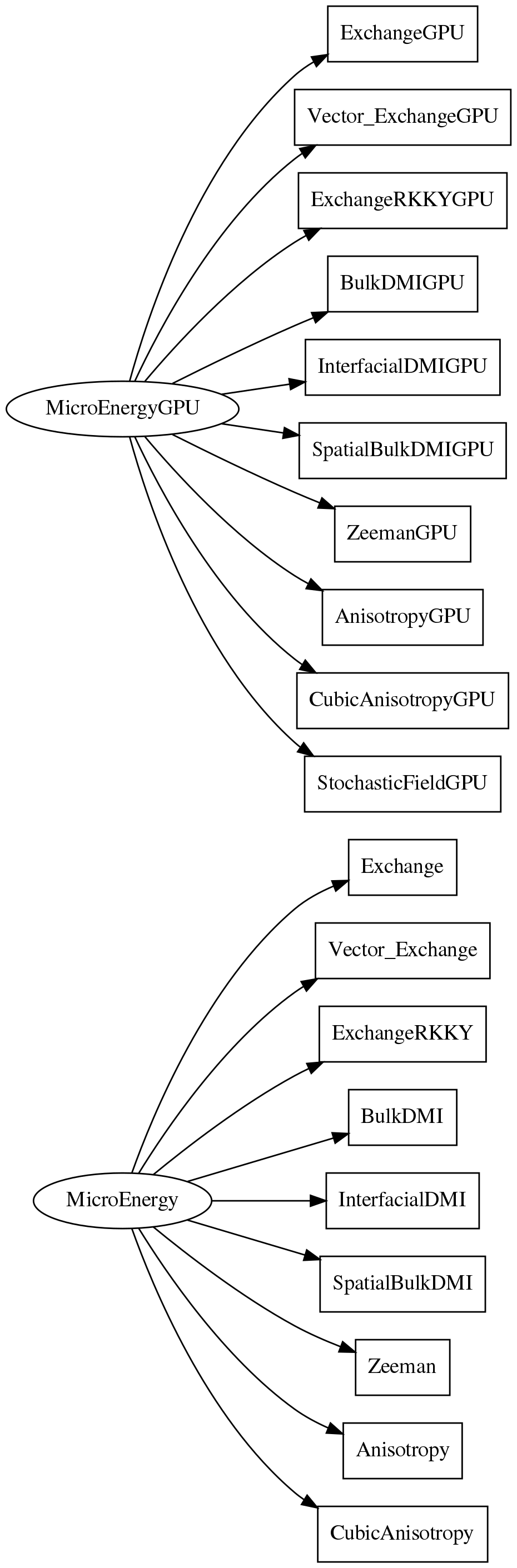
Energy
Reducing the startup time
Julia is a dynamically-typed language, so the input script will be compiled when we start a simulation. However, the typical startup time in our case ranges from 1s to 30s depends on the complexity of the problem. It is painful especially if we run the simulation using GPU. Luckily, we can compile our package using PackageCompiler.jl:
using PackageCompiler
compile_incremental(:JuMag)After finishing the compilation, a dyn.so file will be generated. If we start julia using julia -J /path/to/dyn.so the stratup time will be ignorable.
Note: If you got an error similar to that shown at https://github.com/JuliaLang/PackageCompiler.jl/issues/184, using dev PackageCompiler may solve the issue.
If other errors appear, it is better to figure out which package is failed
compile_incremental(:FFTW, :CUDAdrv, :CUDAnative, :CuArrays, force=false)and remove that package from deps in Project.toml. For example, if CuArrays fails, comment the line
#CuArrays = "3a865a2d-5b23-5a0f-bc46-62713ec82fae"may solve the problem.
LLG equation with Zhang-Li extension
where
and $\mu_B=|e|\hbar/(2m)$ is the Bohr magneton. In LL form
where $\vec{\tau}=(\vec{j}_s \cdot \nabla)\vec{m}$
Note that
so this torque is damping-like torque and the last torque is field-like torque. Therefore, we rewrite the LLG equation in the form
where
Cayley transformation
The LLG equation can be cast into
where the operator \hat{} is defined as
Using the Cayley transfromation, the LLG equation can be written as
where
So one has